Agent to Agent Testing Platform vs LLMWise
Side-by-side comparison to help you choose the right AI tool.
Agent to Agent Testing Platform
TestMu AI is the top platform trusted by millions to autonomously test any AI agent for safety and accuracy.
Last updated: February 28, 2026
LLMWise
Access 62 AI models with one API, auto-routing to the best one for each prompt, and pay only for what you use.
Last updated: February 28, 2026
Visual Comparison
Agent to Agent Testing Platform
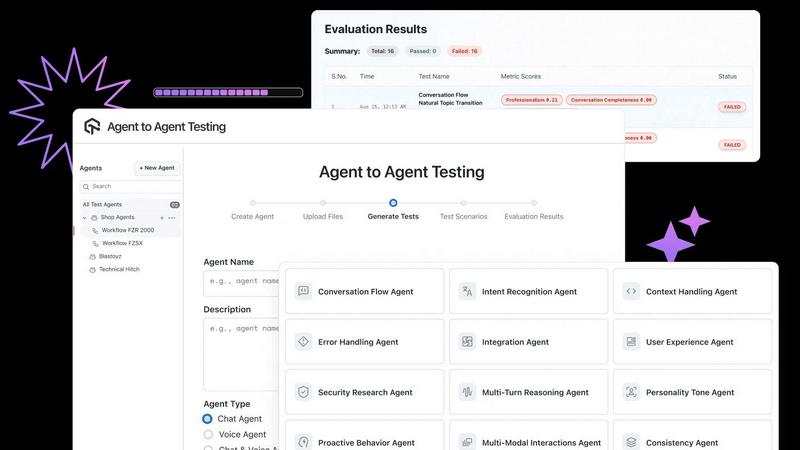
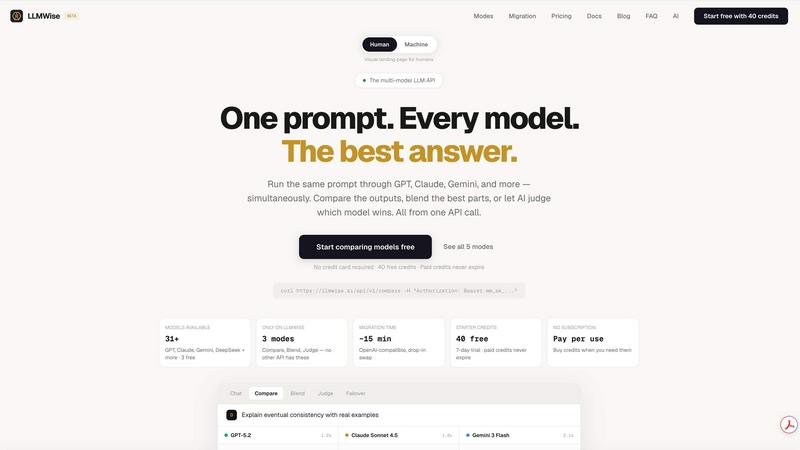
LLMWise
Feature Comparison
Agent to Agent Testing Platform
Autonomous Multi-Agent Test Generation
Leverage a dedicated team of 17+ specialized AI agents designed to act as synthetic testers. These agents autonomously generate diverse, complex test scenarios, simulating countless real-world user interactions to ruthlessly uncover edge cases, bias, toxicity, and hallucination risks that human testers would never think to try, ensuring comprehensive coverage.
True Multi-Modal Understanding & Testing
Go far beyond text-based testing. Define requirements or upload PRDs (Product Requirement Documents) that include diverse inputs like images, audio, and video files. The platform gauges your AI agent's expected output against these multi-modal inputs, mirroring the complex, real-world scenarios your agent will actually face, from analyzing an uploaded image to processing a voice command.
Diverse Persona Testing at Scale
Simulate real human diversity with a library of customizable user personas, such as the "International Caller" or "Digital Novice." This allows you to validate how your AI agent performs for different user types, behaviors, and needs, ensuring inclusivity and effectiveness across your entire user base through autonomous, large-scale synthetic user testing.
Actionable Evaluation with Risk Scoring
Get beyond pass/fail results. Receive detailed, actionable reports in minutes with deep visibility into business metrics, conversational flow, and interaction dynamics. Integrated risk scoring highlights potential areas of concern, allowing teams to prioritize critical issues and optimize performance based on concrete data, not guesswork.
LLMWise
Smart Model Routing
Stop guessing which model to use. LLMWise's intelligent router analyzes your prompt and automatically selects the optimal model from its vast catalog. Send a coding query, and it routes to GPT-4o or a specialized coder model. Submit a creative brief, and Claude Opus gets the call. This dynamic matching ensures you always get the highest quality output for your specific use case, maximizing both performance and cost-efficiency without any manual intervention.
Compare, Blend & Judge Modes
Unlock next-level AI orchestration with four distinct modes. Use Compare to run a single prompt across multiple models simultaneously and see their answers side-by-side in your dashboard. Blend takes it further, querying several models and intelligently synthesizing their best parts into one cohesive, superior response. With Judge mode, you can have models critique and evaluate each other's outputs, providing a layer of automated quality assurance.
Resilient Failover & Circuit Breakers
Guarantee uptime for your AI-powered features. LLMWise's built-in resilience system monitors all provider endpoints. If a primary model like GPT-4o is down or slow, the circuit breaker instantly trips and fails over your request to a pre-configured backup model, like Claude Sonnet. Your application never breaks, and your users never see an error, ensuring seamless reliability.
BYOK & Flexible Credits
Take complete control of your costs. Bring Your Own Keys (BYOK) to use LLMWise's orchestration features while paying directly at provider rates. Alternatively, use the simplicity of LLMWise credits for a unified, pay-as-you-go experience. Start with 20 free credits that never expire, and access 30 permanently free models for prototyping and fallback. No subscriptions, no monthly traps.
Use Cases
Agent to Agent Testing Platform
Pre-Production Validation for Customer Service Bots
Before launching a new customer support chatbot, use the platform to simulate thousands of customer inquiries, from simple FAQ requests to complex, emotional, or poorly-phrased problems. Validate intent recognition, escalation logic to human agents, policy compliance, and tone to ensure a flawless, brand-safe launch.
Compliance and Safety Auditing for Financial AI Agents
For AI agents in regulated industries like finance or healthcare, proactively test for data privacy violations, biased lending or advice, and hallucinated information. The platform's specialized agents (e.g., Data Privacy Agent) can systematically probe for compliance failures and safety risks, providing an audit trail for regulators.
Continuous Regression Testing for Voice Assistants
Every update to your voice AI's model or knowledge base risks breaking a previously working function. Implement autonomous regression testing suites that run with each deployment, checking for consistent intent understanding, tone, and reasoning across key user journeys to prevent updates from degrading the customer experience.
Performance Benchmarking Across Agent Versions
When developing a new version of your AI agent, use the platform's scenario library to run identical test batteries against both the old and new versions. Objectively compare key metrics like effectiveness, accuracy, and empathy to quantify improvement and ensure no regression in core capabilities before switching versions.
LLMWise
AI Application Development
Build robust, multi-model AI applications without the complexity. Developers use LLMWise as their single integration point, leveraging the best model for each function within their app—from customer support chatbots powered by Claude to code-generation features using GPT. The single API and automatic failover make development faster and production deployments infinitely more reliable.
Model Benchmarking & Evaluation
Make data-driven decisions on which model to use. Product teams and AI engineers use the Compare mode to run batch tests and benchmark suites across GPT-5.2, Claude Opus, and Gemini Pro on their exact prompts. Instantly see which is fastest, cheapest, or provides the highest-quality answer for their specific domain, eliminating costly guesswork.
Content Synthesis & Enhancement
Create premium content by blending the strengths of multiple AIs. Content strategists and marketers use Blend mode to generate articles, marketing copy, or product descriptions. The platform queries several top models and merges their strongest arguments, most creative phrasing, and most factual details into one exceptional piece of content that outperforms any single model's output.
Cost Optimization & Prototyping
Drastically reduce AI expenses and experiment freely. Startups and indie hackers use the 30 free, zero-credit models to prototype new features at zero cost. They then use BYOK to plug in their existing API keys, avoiding markups, and set optimization policies to automatically choose the most cost-effective model that meets their quality and speed thresholds.
Overview
About Agent to Agent Testing Platform
Stop gambling with your AI's behavior in production. The Agent to Agent Testing Platform is the world's first AI-native quality assurance framework built specifically for the unpredictable, dynamic world of autonomous AI agents. As chatbots, voice assistants, and phone-caller agents become core to customer experience, traditional software testing methods are completely obsolete. This platform is the definitive solution for enterprises needing to validate AI agents across chat, voice, phone, and multimodal experiences before they go live. It introduces a dedicated assurance layer that moves beyond simple prompt checks to evaluate full, multi-turn conversations and complex interaction patterns. Trusted by over 2 million users globally and powering leaders like Dashlane and Transavia, the platform uses a fleet of 17+ specialized AI agents to autonomously generate tests, simulating thousands of synthetic user interactions to uncover long-tail failures, edge cases, policy violations, and handoff logic flaws that manual testing always misses. It's not just testing; it's your insurance policy for safe, reliable, and effective AI agent deployment.
About LLMWise
Stop juggling multiple AI subscriptions and wrestling with a dozen different API keys. LLMWise is the ultimate AI orchestration platform that gives developers one powerful API to access the entire universe of large language models. We're talking 62+ models from 20 top providers like OpenAI, Anthropic, Google, Meta, xAI, and DeepSeek. The magic? Intelligent routing that automatically matches your specific prompt to the absolute best model for the job. Need code? It goes to GPT. Creative writing? Claude takes the lead. Translation? Gemini handles it. But it's so much more than smart routing. Compare outputs side-by-side, blend the best parts of multiple responses into one superior answer, and even have models judge each other's work. Built with resilience at its core, LLMWise features circuit-breaker failover to keep your app running smoothly even when a major provider has an outage. It's the end of vendor lock-in and the beginning of a smarter, simpler, and more cost-effective way to build with AI. Designed for developers who demand the best performance for every task without the operational nightmare.
Frequently Asked Questions
Agent to Agent Testing Platform FAQ
What makes Agent-to-Agent Testing different from traditional QA?
Traditional QA is built for deterministic, rule-based software with predictable outputs. AI agents are probabilistic, dynamic, and conversational. This platform is AI-native, using other AI agents to test through full multi-turn conversations, understanding context, nuance, and emergent behaviors that scripted tests cannot capture, focusing on metrics like bias and hallucination specific to AI.
Can it test voice and phone-calling AI agents, not just chatbots?
Absolutely. The platform is built for multi-modal experiences. It can simulate and test interactions across chat, voice, hybrid, and dedicated phone-caller agents. You can define test scenarios involving audio inputs and validate the agent's spoken responses, call flow logic, and handoff procedures, just as you would with text-based chatbots.
How does the autonomous test generation work?
The platform employs a suite of over 17 specialized AI agents, each with a role like "Personality Tone Agent" or "Intent Recognition Agent." These agents work together to autonomously create diverse, adversarial, and edge-case test scenarios based on your agent's defined purpose, simulating the unpredictable nature of real human users at massive scale.
Does it integrate with existing development workflows?
Yes, seamlessly. The platform integrates directly with TestMu AI's HyperExecute for large-scale cloud execution, fitting into your CI/CD pipeline. You can automatically trigger test suites on code commits, generate scenarios, and run them at scale in the cloud, receiving actionable feedback and reports within minutes to accelerate your development cycle.
LLMWise FAQ
How does the pricing work?
LLMWise offers incredible flexibility. You can start completely free with 20 trial credits and access to 30 zero-credit models. When you're ready, choose your path: use Bring Your Own Keys (BYOK) to pay your AI providers directly at their standard rates, or purchase LLMWise credits for a simple, unified pay-as-you-go model. There are no monthly subscriptions—you only pay for what you use, and your credits never expire.
What are the free models for?
The 30+ free models (like Google's Gemma 3 series and Meta's Llama 3.3) are a game-changer. Use them to prototype your AI features without spending a cent. They also serve as a smart fallback layer during traffic spikes or provider outages, and are perfect for running quality benchmarks against paid models to inform your routing strategies.
How does the intelligent routing decide?
Our routing engine uses a sophisticated set of rules and learned optimizations. It analyzes your prompt's content, intent, and structure, then matches it against known model strengths—coding, creativity, reasoning, speed, cost, etc. You can also set your own custom routing policies based on performance, cost, or reliability metrics you define.
Is my data safe with LLMWise?
Absolutely. When you use the BYOK (Bring Your Own Keys) mode, your API keys are securely stored and your prompts are sent directly from our infrastructure to the provider's API, following their respective data privacy policies. We act as a secure router, not a data processor. For credits-based usage, we maintain strict data handling protocols.
Alternatives
Agent to Agent Testing Platform Alternatives
Agent to Agent Testing Platform is a pioneering AI-native QA framework in the AI Assistants category. It validates the behavior of autonomous AI agents across chat, voice, phone, and multimodal systems, moving beyond static testing to catch complex, real-world failures. Users often explore alternatives for various reasons. These can include budget constraints, the need for different feature sets like specific integrations or reporting, or simply requiring a platform that aligns better with their existing tech stack and team workflows. When evaluating other options, focus on capabilities that match the complexity of modern AI. Look for solutions that can simulate multi-turn conversations, autonomously generate edge-case tests, validate security and compliance risks, and scale to simulate thousands of synthetic user interactions. The right tool should act as a dedicated assurance layer for unpredictable agentic AI.
LLMWise Alternatives
LLMWise is a unified AI API platform that simplifies access to multiple large language models like GPT, Claude, and Gemini. It falls into the category of AI orchestration tools, designed to intelligently route user prompts to the best-suited model automatically. Users often explore alternatives for various reasons, such as specific pricing models, the need for different feature sets like advanced analytics or custom workflows, or a preference for a platform that integrates more tightly with their existing tech stack. Some may seek simpler tools or more specialized providers. When evaluating other options, key considerations include the range of supported models, the sophistication of routing logic, transparent and flexible pricing without mandatory subscriptions, reliability features like automatic failover, and the depth of testing and optimization tools available to developers.