DeepRails
DeepRails stops AI hallucinations before they reach your users, trusted by engineers everywhere.
Visit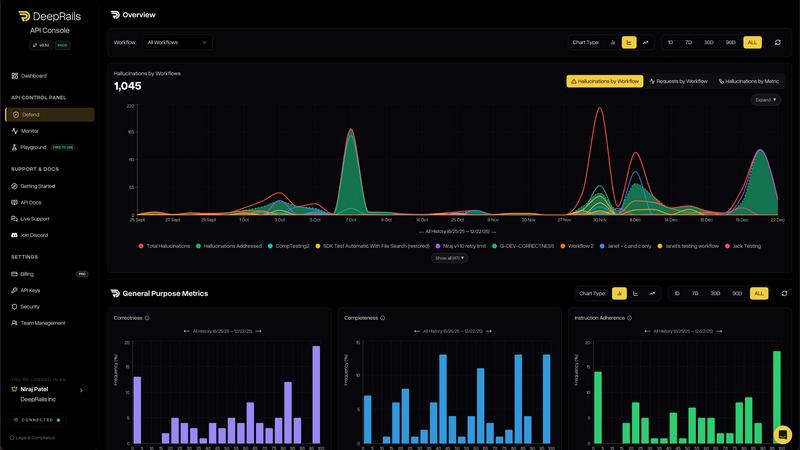
About DeepRails
DeepRails is the essential kill-switch for AI hallucinations, engineered specifically for developers and AI engineers who are serious about shipping reliable, production-grade AI. In an era where large language models (LLMs) are becoming core to business applications, the epidemic of models "making things up" is the single biggest blocker to user trust and adoption. DeepRails tackles this problem head-on as the only comprehensive guardrails platform designed not just to detect inaccuracies with industry-leading precision but to substantively fix them in real-time before any bad output ever reaches your end-users. It's the definitive reliability layer trusted by elite teams in high-stakes sectors like legal, finance, healthcare, and education to deploy AI with unwavering confidence. The platform operates as a model-agnostic suite, evaluating every AI response for factual correctness, grounding, reasoning consistency, and safety, intelligently distinguishing true errors from acceptable model variance. Beyond mere detection, DeepRails powers automated remediation workflows, custom evaluation metrics, and integrated human feedback loops that continuously improve your models. With seamless integration into modern dev pipelines and leading LLM providers, DeepRails transforms trustworthy AI from a distant goal into a deployable, operational reality today.
Features of DeepRails
Defend API: Real-Time Correction Engine
The Defend API is your proactive shield, acting as a real-time correction engine that sits between your LLM and your users. You configure guardrail metrics and thresholds, and for every API call, it automatically scores the model's output for issues like hallucinations. If a problem is detected, it can instantly trigger corrective actions like "FixIt" or "ReGen" to repair or regenerate the response before it's delivered, ensuring only verified, high-quality outputs reach your customers.
Expansive & Custom Guardrail Metrics Library
Move beyond basic checks with DeepRails's expansive library of specialized, hyper-accurate evaluation metrics. Choose from purpose-built metrics like Correctness (for factual accuracy), Completeness, Context Adherence (critical for RAG), and Comprehensive Safety. The platform boasts proven superiority, with metrics like Correctness being 45% more accurate than alternatives like AWS Bedrock. You can also create fully custom metrics tailored to your specific domain and quality requirements.
Full Audit Trails & Performance Analytics
Gain complete visibility into your AI's performance with the DeepRails Console. Every single interaction—from your LLM, through DeepRails's evaluation and remediation, to your customer—is logged in real-time. This provides beautiful, actionable dashboards for key metrics, detailed traces of every "improvement chain" where a hallucination was fixed, and full audit logs essential for compliance, debugging, and continuous model improvement.
Model-Agnostic & Seamless Integration
Built for the real world, DeepRails is fully model-agnostic, working seamlessly with any LLM provider or your own custom models. It integrates directly into your existing production stack and modern dev pipelines with easy-to-use SDKs and a straightforward API. This means you can deploy a robust AI quality control layer without overhauling your entire infrastructure, making advanced guardrails accessible and production-ready from day one.
Use Cases of DeepRails
Legal & Compliance Document Review
In the legal sector, accuracy is non-negotiable. DeepRails ensures AI assistants analyzing case law or drafting legal briefs do not hallucinate critical details like case names, rulings, or citations. The Correctness and Context Adherence guardrails verify every claim against provided source documents, preventing costly errors and maintaining rigorous compliance standards before any advice is given to a client or submitted to court.
Financial Services & Customer Support
For banks and fintech companies using AI for customer advice, portfolio summaries, or market explanations, DeepRails is critical. It automatically fact-checks financial data, ensures numerical accuracy, and validates that all regulatory disclaimers are included and correct. This builds user trust, mitigates regulatory risk, and prevents the dissemination of incorrect financial information that could lead to significant losses.
Healthcare Information & Triage Chatbots
Healthcare AI applications demand extreme reliability. DeepRails safeguards patient-facing chatbots and diagnostic support tools by rigorously evaluating outputs for factual medical accuracy, checking drug interaction lists against verified databases, and filtering out any unsupported or dangerous health recommendations. The Comprehensive Safety guardrail also detects and redacts any accidentally leaked PII for HIPAA compliance.
Educational Content & Tutoring Systems
Educational platforms using AI tutors or content generators rely on DeepRails to guarantee the instructional material is factually correct, complete, and pedagogically sound. It ensures complex concepts are explained accurately, quiz answers are right, and that the AI doesn't invent historical events or scientific facts. This preserves educational integrity and provides a safe, reliable learning environment for students.
Frequently Asked Questions
How does DeepRails actually "fix" a hallucination?
DeepRails employs automated remediation workflows triggered when a guardrail score falls below your threshold. The primary methods are "FixIt," which attempts to correct the specific inaccurate part of the output using reasoning and verification, and "ReGen," which instructs your LLM to regenerate a completely new response, often with improved instructions. The fixed output is then re-evaluated before being sent to the user, creating a seamless improvement chain.
Is DeepRails only for detecting factual errors?
No, while ultra-accurate hallucination detection is its core strength, DeepRails is a complete AI quality control platform. Its expansive library includes guardrails for Completeness, Instruction Adherence, Safety (PII, hate speech, etc.), and Context Adherence for RAG. This allows you to monitor and enforce a wide range of quality, safety, and compliance requirements beyond simple fact-checking.
How do I integrate DeepRails into my existing AI pipeline?
Integration is designed to be straightforward for developers. You can add the DeepRails Defend API as a middleware layer in your application's backend with just a few lines of code using our SDKs (Python, Node.js, etc.). It intercepts calls to your LLM provider (like OpenAI, Anthropic, or self-hosted models), evaluates the response, and returns the guarded result. No changes to your core AI models are required.
What makes DeepRails more accurate than other evaluation tools?
DeepRails's metrics are built with a focus on production-grade precision, using advanced techniques to distinguish true hallucinations from acceptable paraphrasing or stylistic variance. This results in significantly lower false-positive rates. The platform's own data benchmarks its core Correctness metric as 45% more accurate than AWS Bedrock's equivalent, based on rigorous testing against real-world, high-stakes use cases.